mirror of
https://github.com/ddnet/ddnet.git
synced 2024-11-10 01:58:19 +00:00
Merge #5897
5897: Add tests for various string functions, make `str_comp_filenames` case insensitive and use it again for sorting filenames r=def- a=Robyt3 See commit messages for most changes. See the following screenshots that show how sorting of maps and demos is changed. Sorting with `str_comp_nocase`: 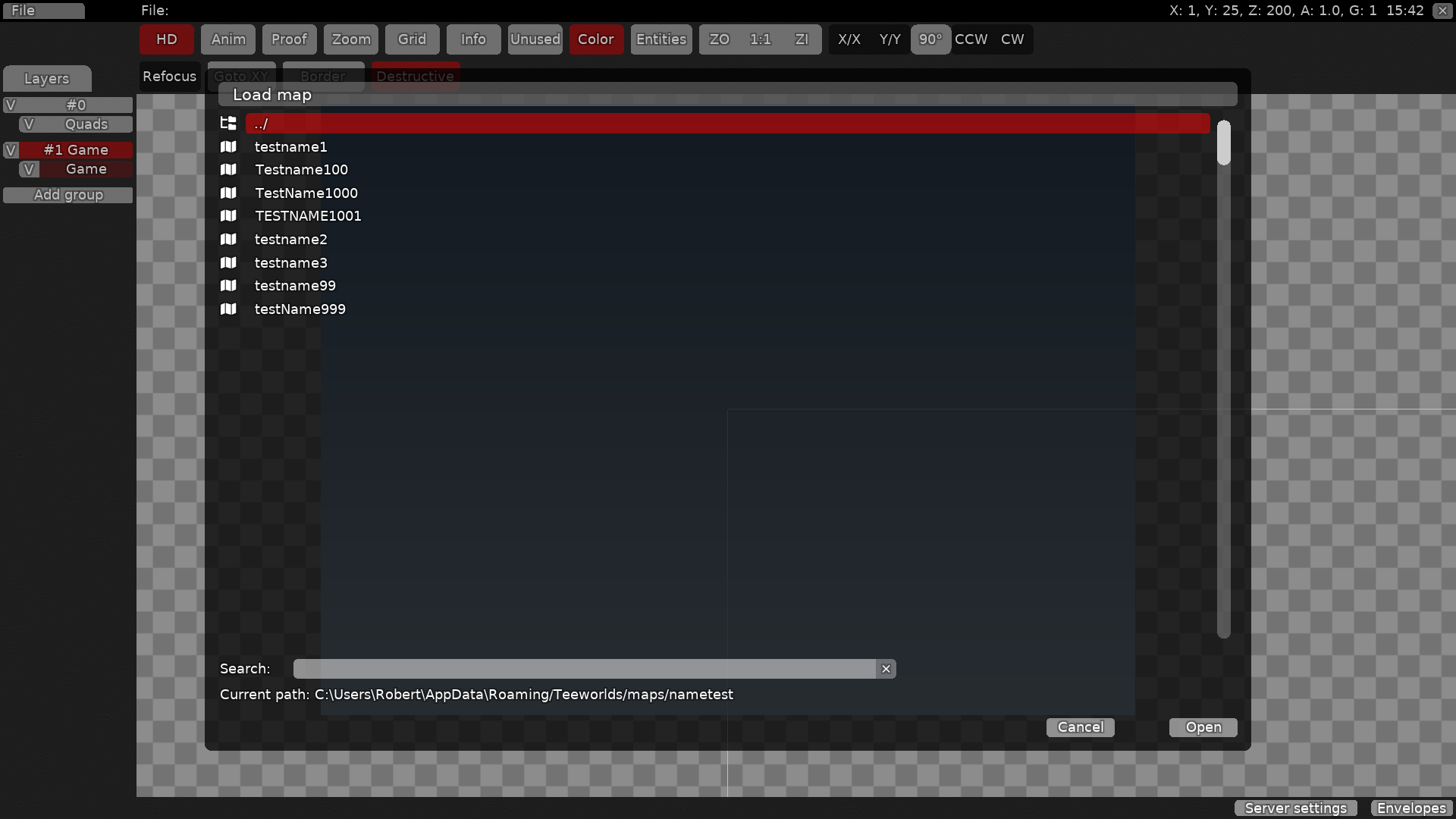 Sorting with `str_comp_filenames`, which is now also sorting case insensitive: 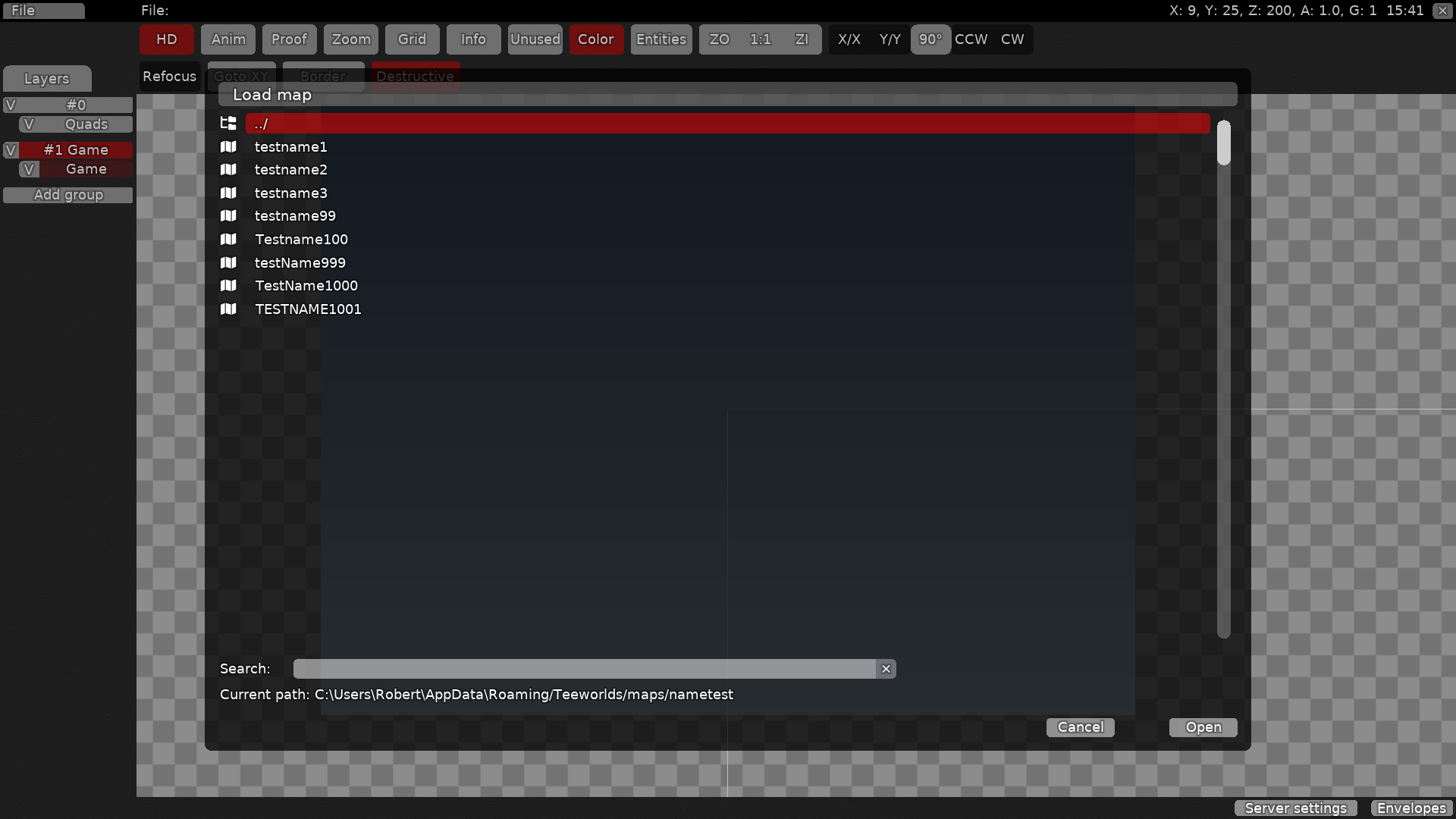 ## Checklist - [X] Tested the change ingame - [X] Provided screenshots if it is a visual change - [ ] Tested in combination with possibly related configuration options - [X] Written a unit test (especially base/) or added coverage to integration test - [X] Considered possible null pointers and out of bounds array indexing - [X] Changed no physics that affect existing maps - [ ] Tested the change with [ASan+UBSan or valgrind's memcheck](https://github.com/ddnet/ddnet/#using-addresssanitizer--undefinedbehavioursanitizer-or-valgrinds-memcheck) (optional) Co-authored-by: Robert Müller <robytemueller@gmail.com>
{kind=link}
{kind=link}
This commit is contained in:
commit
c0fe997a39
|
|
@ -2648,11 +2648,13 @@ int str_format(char *buffer, int buffer_size, const char *format, ...)
|
|||
return str_utf8_fix_truncation(buffer);
|
||||
}
|
||||
|
||||
char *str_trim_words(char *str, int words)
|
||||
const char *str_trim_words(const char *str, int words)
|
||||
{
|
||||
while(*str && str_isspace(*str))
|
||||
str++;
|
||||
while(words && *str)
|
||||
{
|
||||
if(isspace(*str) && !isspace(*(str + 1)))
|
||||
if(str_isspace(*str) && !str_isspace(*(str + 1)))
|
||||
words--;
|
||||
str++;
|
||||
}
|
||||
|
|
@ -2742,28 +2744,28 @@ void str_clean_whitespaces(char *str_in)
|
|||
|
||||
char *str_skip_to_whitespace(char *str)
|
||||
{
|
||||
while(*str && (*str != ' ' && *str != '\t' && *str != '\n'))
|
||||
while(*str && !str_isspace(*str))
|
||||
str++;
|
||||
return str;
|
||||
}
|
||||
|
||||
const char *str_skip_to_whitespace_const(const char *str)
|
||||
{
|
||||
while(*str && (*str != ' ' && *str != '\t' && *str != '\n'))
|
||||
while(*str && !str_isspace(*str))
|
||||
str++;
|
||||
return str;
|
||||
}
|
||||
|
||||
char *str_skip_whitespaces(char *str)
|
||||
{
|
||||
while(*str && (*str == ' ' || *str == '\t' || *str == '\n' || *str == '\r'))
|
||||
while(*str && str_isspace(*str))
|
||||
str++;
|
||||
return str;
|
||||
}
|
||||
|
||||
const char *str_skip_whitespaces_const(const char *str)
|
||||
{
|
||||
while(*str && (*str == ' ' || *str == '\t' || *str == '\n' || *str == '\r'))
|
||||
while(*str && str_isspace(*str))
|
||||
str++;
|
||||
return str;
|
||||
}
|
||||
|
|
@ -2822,8 +2824,9 @@ int str_comp_filenames(const char *a, const char *b)
|
|||
return result;
|
||||
}
|
||||
|
||||
if(*a != *b)
|
||||
break;
|
||||
result = tolower(*a) - tolower(*b);
|
||||
if(result)
|
||||
return result;
|
||||
}
|
||||
return *a - *b;
|
||||
}
|
||||
|
|
@ -3038,15 +3041,16 @@ int str_countchr(const char *haystack, char needle)
|
|||
void str_hex(char *dst, int dst_size, const void *data, int data_size)
|
||||
{
|
||||
static const char hex[] = "0123456789ABCDEF";
|
||||
int b;
|
||||
|
||||
for(b = 0; b < data_size && b < dst_size / 4 - 4; b++)
|
||||
int data_index;
|
||||
int dst_index;
|
||||
for(data_index = 0, dst_index = 0; data_index < data_size && dst_index < dst_size - 3; data_index++)
|
||||
{
|
||||
dst[b * 3] = hex[((const unsigned char *)data)[b] >> 4];
|
||||
dst[b * 3 + 1] = hex[((const unsigned char *)data)[b] & 0xf];
|
||||
dst[b * 3 + 2] = ' ';
|
||||
dst[b * 3 + 3] = 0;
|
||||
dst[data_index * 3] = hex[((const unsigned char *)data)[data_index] >> 4];
|
||||
dst[data_index * 3 + 1] = hex[((const unsigned char *)data)[data_index] & 0xf];
|
||||
dst[data_index * 3 + 2] = ' ';
|
||||
dst_index += 3;
|
||||
}
|
||||
dst[dst_index] = '\0';
|
||||
}
|
||||
|
||||
static int hexval(char x)
|
||||
|
|
@ -3369,7 +3373,10 @@ void net_stats(NETSTATS *stats_inout)
|
|||
*stats_inout = network_stats;
|
||||
}
|
||||
|
||||
int str_isspace(char c) { return c == ' ' || c == '\n' || c == '\t'; }
|
||||
int str_isspace(char c)
|
||||
{
|
||||
return c == ' ' || c == '\n' || c == '\r' || c == '\t';
|
||||
}
|
||||
|
||||
char str_uppercase(char c)
|
||||
{
|
||||
|
|
|
|||
|
|
@ -1246,8 +1246,9 @@ int str_format(char *buffer, int buffer_size, const char *format, ...)
|
|||
* @return Trimmed string
|
||||
*
|
||||
* @remark The strings are treated as zero-terminated strings.
|
||||
* @remark Leading whitespace is always trimmed.
|
||||
*/
|
||||
char *str_trim_words(char *str, int words);
|
||||
const char *str_trim_words(const char *str, int words);
|
||||
|
||||
/**
|
||||
* Check whether string has ASCII control characters.
|
||||
|
|
@ -1301,12 +1302,12 @@ void str_sanitize_filename(char *str);
|
|||
*
|
||||
* @param str String to clean up
|
||||
*
|
||||
* @remark The strings are treated as zero-termineted strings.
|
||||
* @remark The strings are treated as zero-terminated strings.
|
||||
*/
|
||||
void str_clean_whitespaces(char *str);
|
||||
|
||||
/**
|
||||
* Skips leading non-whitespace characters(all but ' ', '\t', '\n', '\r').
|
||||
* Skips leading non-whitespace characters.
|
||||
*
|
||||
* @ingroup Strings
|
||||
*
|
||||
|
|
@ -1316,6 +1317,7 @@ void str_clean_whitespaces(char *str);
|
|||
* within the string.
|
||||
*
|
||||
* @remark The strings are treated as zero-terminated strings.
|
||||
* @remark Whitespace is defined according to str_isspace.
|
||||
*/
|
||||
char *str_skip_to_whitespace(char *str);
|
||||
|
||||
|
|
@ -1326,7 +1328,7 @@ char *str_skip_to_whitespace(char *str);
|
|||
const char *str_skip_to_whitespace_const(const char *str);
|
||||
|
||||
/**
|
||||
* Skips leading whitespace characters(' ', '\t', '\n', '\r').
|
||||
* Skips leading whitespace characters.
|
||||
*
|
||||
* @ingroup Strings
|
||||
*
|
||||
|
|
@ -1336,6 +1338,7 @@ const char *str_skip_to_whitespace_const(const char *str);
|
|||
* within the string.
|
||||
*
|
||||
* @remark The strings are treated as zero-terminated strings.
|
||||
* @remark Whitespace is defined according to str_isspace.
|
||||
*/
|
||||
char *str_skip_whitespaces(char *str);
|
||||
|
||||
|
|
@ -1415,7 +1418,7 @@ int str_comp(const char *a, const char *b);
|
|||
int str_comp_num(const char *a, const char *b, int num);
|
||||
|
||||
/**
|
||||
* Compares two strings case sensitive, digit chars will be compared as numbers.
|
||||
* Compares two strings case insensitive, digit chars will be compared as numbers.
|
||||
*
|
||||
* @ingroup Strings
|
||||
*
|
||||
|
|
@ -1584,38 +1587,36 @@ const char *str_find_nocase(const char *haystack, const char *needle);
|
|||
*/
|
||||
const char *str_find(const char *haystack, const char *needle);
|
||||
|
||||
/*
|
||||
Function: str_rchr
|
||||
Finds the last occurance of a character
|
||||
/**
|
||||
* Finds the last occurance of a character
|
||||
*
|
||||
* @ingroup Strings
|
||||
*
|
||||
* @param haystack String to search in
|
||||
* @param needle Character to search for
|
||||
|
||||
Parameters:
|
||||
haystack - String to search in
|
||||
needle - Character to search for
|
||||
|
||||
Returns:
|
||||
A pointer into haystack where the needle was found.
|
||||
Returns NULL if needle could not be found.
|
||||
|
||||
Remarks:
|
||||
- The strings are treated as zero-terminated strings.
|
||||
*/
|
||||
* @return A pointer into haystack where the needle was found.
|
||||
* Returns NULL if needle could not be found.
|
||||
*
|
||||
* @remark The strings are treated as zero-terminated strings.
|
||||
* @remark The zero-terminator character can also be found with this function.
|
||||
*/
|
||||
const char *str_rchr(const char *haystack, char needle);
|
||||
|
||||
/*
|
||||
Function: str_countchr
|
||||
Counts the number of occurrences of a character in a string.
|
||||
/**
|
||||
* Counts the number of occurrences of a character in a string.
|
||||
*
|
||||
* @ingroup Strings
|
||||
*
|
||||
* @param haystack String to count in
|
||||
* @param needle Character to count
|
||||
|
||||
Parameters:
|
||||
haystack - String to count in
|
||||
needle - Character to count
|
||||
|
||||
Returns:
|
||||
The number of characters in the haystack string matching
|
||||
the needle character.
|
||||
|
||||
Remarks:
|
||||
- The strings are treated as zero-terminated strings.
|
||||
*/
|
||||
* @return The number of characters in the haystack string matching
|
||||
* the needle character.
|
||||
*
|
||||
* @remark The strings are treated as zero-terminated strings.
|
||||
* @remark The number of zero-terminator characters cannot be counted.
|
||||
*/
|
||||
int str_countchr(const char *haystack, char needle);
|
||||
|
||||
/*
|
||||
|
|
@ -2029,7 +2030,20 @@ int str_toint(const char *str);
|
|||
int str_toint_base(const char *str, int base);
|
||||
unsigned long str_toulong_base(const char *str, int base);
|
||||
float str_tofloat(const char *str);
|
||||
|
||||
/**
|
||||
* Determines whether a character is whitespace.
|
||||
*
|
||||
* @ingroup Strings
|
||||
*
|
||||
* @param c the character to check
|
||||
*
|
||||
* @return 1 if the character is whitespace, 0 otherwise.
|
||||
*
|
||||
* @remark The following characters are considered whitespace: ' ', '\n', '\r', '\t'
|
||||
*/
|
||||
int str_isspace(char c);
|
||||
|
||||
char str_uppercase(char c);
|
||||
int str_isallnum(const char *str);
|
||||
unsigned str_quickhash(const char *str);
|
||||
|
|
|
|||
|
|
@ -414,7 +414,7 @@ protected:
|
|||
const CDemoItem &Right = g_Config.m_BrDemoSortOrder ? *this : Other;
|
||||
|
||||
if(g_Config.m_BrDemoSort == SORT_DEMONAME)
|
||||
return str_comp_nocase(Left.m_aFilename, Right.m_aFilename) < 0;
|
||||
return str_comp_filenames(Left.m_aFilename, Right.m_aFilename) < 0;
|
||||
if(g_Config.m_BrDemoSort == SORT_DATE)
|
||||
return Left.m_Date < Right.m_Date;
|
||||
|
||||
|
|
|
|||
|
|
@ -955,7 +955,7 @@ public:
|
|||
int m_StorageType;
|
||||
bool m_IsVisible;
|
||||
|
||||
bool operator<(const CFilelistItem &Other) const { return !str_comp(m_aFilename, "..") ? true : !str_comp(Other.m_aFilename, "..") ? false : m_IsDir && !Other.m_IsDir ? true : !m_IsDir && Other.m_IsDir ? false : str_comp_nocase(m_aFilename, Other.m_aFilename) < 0; }
|
||||
bool operator<(const CFilelistItem &Other) const { return !str_comp(m_aFilename, "..") ? true : !str_comp(Other.m_aFilename, "..") ? false : m_IsDir && !Other.m_IsDir ? true : !m_IsDir && Other.m_IsDir ? false : str_comp_filenames(m_aFilename, Other.m_aFilename) < 0; }
|
||||
};
|
||||
std::vector<CFilelistItem> m_vFileList;
|
||||
int m_FilesStartAt;
|
||||
|
|
|
|||
273
src/test/str.cpp
273
src/test/str.cpp
|
|
@ -200,6 +200,38 @@ TEST(Str, EndswithNocase)
|
|||
str_length(ABCDEFG) - str_length(DEFG));
|
||||
}
|
||||
|
||||
TEST(Str, HexEncode)
|
||||
{
|
||||
char aOut[64];
|
||||
const char *pData = "ABCD";
|
||||
str_hex(aOut, sizeof(aOut), pData, 0);
|
||||
EXPECT_STREQ(aOut, "");
|
||||
str_hex(aOut, sizeof(aOut), pData, 1);
|
||||
EXPECT_STREQ(aOut, "41 ");
|
||||
str_hex(aOut, sizeof(aOut), pData, 2);
|
||||
EXPECT_STREQ(aOut, "41 42 ");
|
||||
str_hex(aOut, sizeof(aOut), pData, 3);
|
||||
EXPECT_STREQ(aOut, "41 42 43 ");
|
||||
str_hex(aOut, sizeof(aOut), pData, 4);
|
||||
EXPECT_STREQ(aOut, "41 42 43 44 ");
|
||||
str_hex(aOut, 1, pData, 4);
|
||||
EXPECT_STREQ(aOut, "");
|
||||
str_hex(aOut, 2, pData, 4);
|
||||
EXPECT_STREQ(aOut, "");
|
||||
str_hex(aOut, 3, pData, 4);
|
||||
EXPECT_STREQ(aOut, "");
|
||||
str_hex(aOut, 4, pData, 4);
|
||||
EXPECT_STREQ(aOut, "41 ");
|
||||
str_hex(aOut, 5, pData, 4);
|
||||
EXPECT_STREQ(aOut, "41 ");
|
||||
str_hex(aOut, 6, pData, 4);
|
||||
EXPECT_STREQ(aOut, "41 ");
|
||||
str_hex(aOut, 7, pData, 4);
|
||||
EXPECT_STREQ(aOut, "41 42 ");
|
||||
str_hex(aOut, 8, pData, 4);
|
||||
EXPECT_STREQ(aOut, "41 42 ");
|
||||
}
|
||||
|
||||
TEST(Str, HexDecode)
|
||||
{
|
||||
char aOut[5] = {'a', 'b', 'c', 'd', 0};
|
||||
|
|
@ -374,6 +406,30 @@ TEST(Str, FormatTruncate)
|
|||
EXPECT_STREQ(aBuf, "DDNet最好了");
|
||||
}
|
||||
|
||||
TEST(Str, TrimWords)
|
||||
{
|
||||
const char *pStr1 = "aa bb ccc dddd eeeee";
|
||||
EXPECT_STREQ(str_trim_words(pStr1, 0), "aa bb ccc dddd eeeee");
|
||||
EXPECT_STREQ(str_trim_words(pStr1, 1), "bb ccc dddd eeeee");
|
||||
EXPECT_STREQ(str_trim_words(pStr1, 2), "ccc dddd eeeee");
|
||||
EXPECT_STREQ(str_trim_words(pStr1, 3), "dddd eeeee");
|
||||
EXPECT_STREQ(str_trim_words(pStr1, 4), "eeeee");
|
||||
EXPECT_STREQ(str_trim_words(pStr1, 5), "");
|
||||
EXPECT_STREQ(str_trim_words(pStr1, 100), "");
|
||||
const char *pStr2 = " aaa bb ";
|
||||
EXPECT_STREQ(str_trim_words(pStr2, 0), "aaa bb ");
|
||||
EXPECT_STREQ(str_trim_words(pStr2, 1), "bb ");
|
||||
EXPECT_STREQ(str_trim_words(pStr2, 2), "");
|
||||
EXPECT_STREQ(str_trim_words(pStr2, 100), "");
|
||||
const char *pStr3 = "\n\naa bb\t\tccc\r\n\r\ndddd";
|
||||
EXPECT_STREQ(str_trim_words(pStr3, 0), "aa bb\t\tccc\r\n\r\ndddd");
|
||||
EXPECT_STREQ(str_trim_words(pStr3, 1), "bb\t\tccc\r\n\r\ndddd");
|
||||
EXPECT_STREQ(str_trim_words(pStr3, 2), "ccc\r\n\r\ndddd");
|
||||
EXPECT_STREQ(str_trim_words(pStr3, 3), "dddd");
|
||||
EXPECT_STREQ(str_trim_words(pStr3, 4), "");
|
||||
EXPECT_STREQ(str_trim_words(pStr3, 100), "");
|
||||
}
|
||||
|
||||
TEST(Str, CopyNum)
|
||||
{
|
||||
const char *pFoo = "Foobaré";
|
||||
|
|
@ -530,7 +586,6 @@ TEST(Str, HasCc)
|
|||
EXPECT_FALSE(str_has_cc("a"));
|
||||
EXPECT_FALSE(str_has_cc("Merhaba dünya!"));
|
||||
|
||||
EXPECT_TRUE(str_has_cc("\n"));
|
||||
EXPECT_TRUE(str_has_cc("\n"));
|
||||
EXPECT_TRUE(str_has_cc("\r"));
|
||||
EXPECT_TRUE(str_has_cc("\t"));
|
||||
|
|
@ -538,4 +593,220 @@ TEST(Str, HasCc)
|
|||
EXPECT_TRUE(str_has_cc("a\rb"));
|
||||
EXPECT_TRUE(str_has_cc("\tb"));
|
||||
EXPECT_TRUE(str_has_cc("\n\n"));
|
||||
EXPECT_TRUE(str_has_cc("\x1C"));
|
||||
EXPECT_TRUE(str_has_cc("\x1D"));
|
||||
EXPECT_TRUE(str_has_cc("\x1E"));
|
||||
EXPECT_TRUE(str_has_cc("\x1F"));
|
||||
}
|
||||
|
||||
TEST(Str, SanitizeCc)
|
||||
{
|
||||
char aBuf[64];
|
||||
str_copy(aBuf, "");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, "");
|
||||
str_copy(aBuf, "a");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, "a");
|
||||
str_copy(aBuf, "Merhaba dünya!");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, "Merhaba dünya!");
|
||||
|
||||
str_copy(aBuf, "\n");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\r");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\t");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "a\n");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, "a ");
|
||||
str_copy(aBuf, "a\rb");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, "a b");
|
||||
str_copy(aBuf, "\tb");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " b");
|
||||
str_copy(aBuf, "\n\n");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\x1C");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\x1D");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\x1E");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\x1F");
|
||||
str_sanitize_cc(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
}
|
||||
|
||||
TEST(Str, Sanitize)
|
||||
{
|
||||
char aBuf[64];
|
||||
str_copy(aBuf, "");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "");
|
||||
str_copy(aBuf, "a");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "a");
|
||||
str_copy(aBuf, "Merhaba dünya!");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "Merhaba dünya!");
|
||||
str_copy(aBuf, "\n");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "\n");
|
||||
str_copy(aBuf, "\r");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "\r");
|
||||
str_copy(aBuf, "\t");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "\t");
|
||||
str_copy(aBuf, "a\n");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "a\n");
|
||||
str_copy(aBuf, "a\rb");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "a\rb");
|
||||
str_copy(aBuf, "\tb");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "\tb");
|
||||
str_copy(aBuf, "\n\n");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, "\n\n");
|
||||
|
||||
str_copy(aBuf, "\x1C");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\x1D");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\x1E");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
str_copy(aBuf, "\x1F");
|
||||
str_sanitize(aBuf);
|
||||
EXPECT_STREQ(aBuf, " ");
|
||||
}
|
||||
|
||||
TEST(Str, CleanWhitespaces)
|
||||
{
|
||||
char aBuf[64];
|
||||
str_copy(aBuf, "aa bb ccc dddd eeeee");
|
||||
str_clean_whitespaces(aBuf);
|
||||
EXPECT_STREQ(aBuf, "aa bb ccc dddd eeeee");
|
||||
str_copy(aBuf, " ");
|
||||
str_clean_whitespaces(aBuf);
|
||||
EXPECT_STREQ(aBuf, "");
|
||||
str_copy(aBuf, " aa");
|
||||
str_clean_whitespaces(aBuf);
|
||||
EXPECT_STREQ(aBuf, "aa");
|
||||
str_copy(aBuf, "aa ");
|
||||
str_clean_whitespaces(aBuf);
|
||||
EXPECT_STREQ(aBuf, "aa");
|
||||
str_copy(aBuf, " aa bb ccc dddd eeeee ");
|
||||
str_clean_whitespaces(aBuf);
|
||||
EXPECT_STREQ(aBuf, "aa bb ccc dddd eeeee");
|
||||
}
|
||||
|
||||
TEST(Str, SkipToWhitespace)
|
||||
{
|
||||
char aBuf[64];
|
||||
str_copy(aBuf, "");
|
||||
EXPECT_EQ(str_skip_to_whitespace(aBuf), aBuf);
|
||||
EXPECT_EQ(str_skip_to_whitespace_const(aBuf), aBuf);
|
||||
str_copy(aBuf, " a");
|
||||
EXPECT_EQ(str_skip_to_whitespace(aBuf), aBuf);
|
||||
EXPECT_EQ(str_skip_to_whitespace_const(aBuf), aBuf);
|
||||
str_copy(aBuf, "aaaa b");
|
||||
EXPECT_EQ(str_skip_to_whitespace(aBuf), aBuf + 4);
|
||||
EXPECT_EQ(str_skip_to_whitespace_const(aBuf), aBuf + 4);
|
||||
str_copy(aBuf, "aaaa\n\nb");
|
||||
EXPECT_EQ(str_skip_to_whitespace(aBuf), aBuf + 4);
|
||||
EXPECT_EQ(str_skip_to_whitespace_const(aBuf), aBuf + 4);
|
||||
str_copy(aBuf, "aaaa\r\rb");
|
||||
EXPECT_EQ(str_skip_to_whitespace(aBuf), aBuf + 4);
|
||||
EXPECT_EQ(str_skip_to_whitespace_const(aBuf), aBuf + 4);
|
||||
str_copy(aBuf, "aaaa\t\tb");
|
||||
EXPECT_EQ(str_skip_to_whitespace(aBuf), aBuf + 4);
|
||||
EXPECT_EQ(str_skip_to_whitespace_const(aBuf), aBuf + 4);
|
||||
}
|
||||
|
||||
TEST(Str, SkipWhitespaces)
|
||||
{
|
||||
char aBuf[64];
|
||||
str_copy(aBuf, "");
|
||||
EXPECT_EQ(str_skip_whitespaces(aBuf), aBuf);
|
||||
EXPECT_EQ(str_skip_whitespaces_const(aBuf), aBuf);
|
||||
str_copy(aBuf, "aaaa");
|
||||
EXPECT_EQ(str_skip_whitespaces(aBuf), aBuf);
|
||||
EXPECT_EQ(str_skip_whitespaces_const(aBuf), aBuf);
|
||||
str_copy(aBuf, " \n\r\taaaa");
|
||||
EXPECT_EQ(str_skip_whitespaces(aBuf), aBuf + 4);
|
||||
EXPECT_EQ(str_skip_whitespaces_const(aBuf), aBuf + 4);
|
||||
}
|
||||
|
||||
TEST(Str, CompFilename)
|
||||
{
|
||||
EXPECT_EQ(str_comp_filenames("a", "a"), 0);
|
||||
EXPECT_LT(str_comp_filenames("a", "b"), 0);
|
||||
EXPECT_GT(str_comp_filenames("b", "a"), 0);
|
||||
EXPECT_EQ(str_comp_filenames("A", "a"), 0);
|
||||
EXPECT_LT(str_comp_filenames("A", "b"), 0);
|
||||
EXPECT_GT(str_comp_filenames("b", "A"), 0);
|
||||
EXPECT_LT(str_comp_filenames("a", "B"), 0);
|
||||
EXPECT_GT(str_comp_filenames("B", "a"), 0);
|
||||
EXPECT_LT(str_comp_filenames("abc", "abcd"), 0);
|
||||
EXPECT_GT(str_comp_filenames("abcd", "abc"), 0);
|
||||
EXPECT_LT(str_comp_filenames("abc2", "abcd1"), 0);
|
||||
EXPECT_GT(str_comp_filenames("abcd1", "abc2"), 0);
|
||||
EXPECT_LT(str_comp_filenames("abc50", "abcd"), 0);
|
||||
EXPECT_GT(str_comp_filenames("abcd", "abc50"), 0);
|
||||
EXPECT_EQ(str_comp_filenames("file0", "file0"), 0);
|
||||
EXPECT_LT(str_comp_filenames("file0", "file1"), 0);
|
||||
EXPECT_GT(str_comp_filenames("file1", "file0"), 0);
|
||||
EXPECT_LT(str_comp_filenames("file13", "file37"), 0);
|
||||
EXPECT_GT(str_comp_filenames("file37", "file13"), 0);
|
||||
EXPECT_LT(str_comp_filenames("file13.ext", "file37.ext"), 0);
|
||||
EXPECT_GT(str_comp_filenames("file37.ext", "file13.ext"), 0);
|
||||
EXPECT_LT(str_comp_filenames("FILE13.EXT", "file37.ext"), 0);
|
||||
EXPECT_GT(str_comp_filenames("file37.ext", "FILE13.EXT"), 0);
|
||||
EXPECT_LT(str_comp_filenames("file42", "file1337"), 0);
|
||||
EXPECT_GT(str_comp_filenames("file1337", "file42"), 0);
|
||||
EXPECT_LT(str_comp_filenames("file42.ext", "file1337.ext"), 0);
|
||||
EXPECT_GT(str_comp_filenames("file1337.ext", "file42.ext"), 0);
|
||||
EXPECT_GT(str_comp_filenames("file4414520", "file2055"), 0);
|
||||
EXPECT_LT(str_comp_filenames("file4414520", "file205523151812419"), 0);
|
||||
}
|
||||
|
||||
TEST(Str, RightChar)
|
||||
{
|
||||
const char *pStr = "a bb ccc dddd eeeee";
|
||||
EXPECT_EQ(str_rchr(pStr, 'a'), pStr);
|
||||
EXPECT_EQ(str_rchr(pStr, 'b'), pStr + 3);
|
||||
EXPECT_EQ(str_rchr(pStr, 'c'), pStr + 7);
|
||||
EXPECT_EQ(str_rchr(pStr, 'd'), pStr + 12);
|
||||
EXPECT_EQ(str_rchr(pStr, ' '), pStr + 19);
|
||||
EXPECT_EQ(str_rchr(pStr, 'e'), pStr + 24);
|
||||
EXPECT_EQ(str_rchr(pStr, '\0'), pStr + str_length(pStr));
|
||||
EXPECT_EQ(str_rchr(pStr, 'y'), nullptr);
|
||||
}
|
||||
|
||||
TEST(Str, CountChar)
|
||||
{
|
||||
const char *pStr = "a bb ccc dddd eeeee";
|
||||
EXPECT_EQ(str_countchr(pStr, 'a'), 1);
|
||||
EXPECT_EQ(str_countchr(pStr, 'b'), 2);
|
||||
EXPECT_EQ(str_countchr(pStr, 'c'), 3);
|
||||
EXPECT_EQ(str_countchr(pStr, 'd'), 4);
|
||||
EXPECT_EQ(str_countchr(pStr, 'e'), 5);
|
||||
EXPECT_EQ(str_countchr(pStr, ' '), 10);
|
||||
EXPECT_EQ(str_countchr(pStr, '\0'), 0);
|
||||
EXPECT_EQ(str_countchr(pStr, 'y'), 0);
|
||||
}
|
||||
|
|
|
|||
Loading…
Reference in a new issue